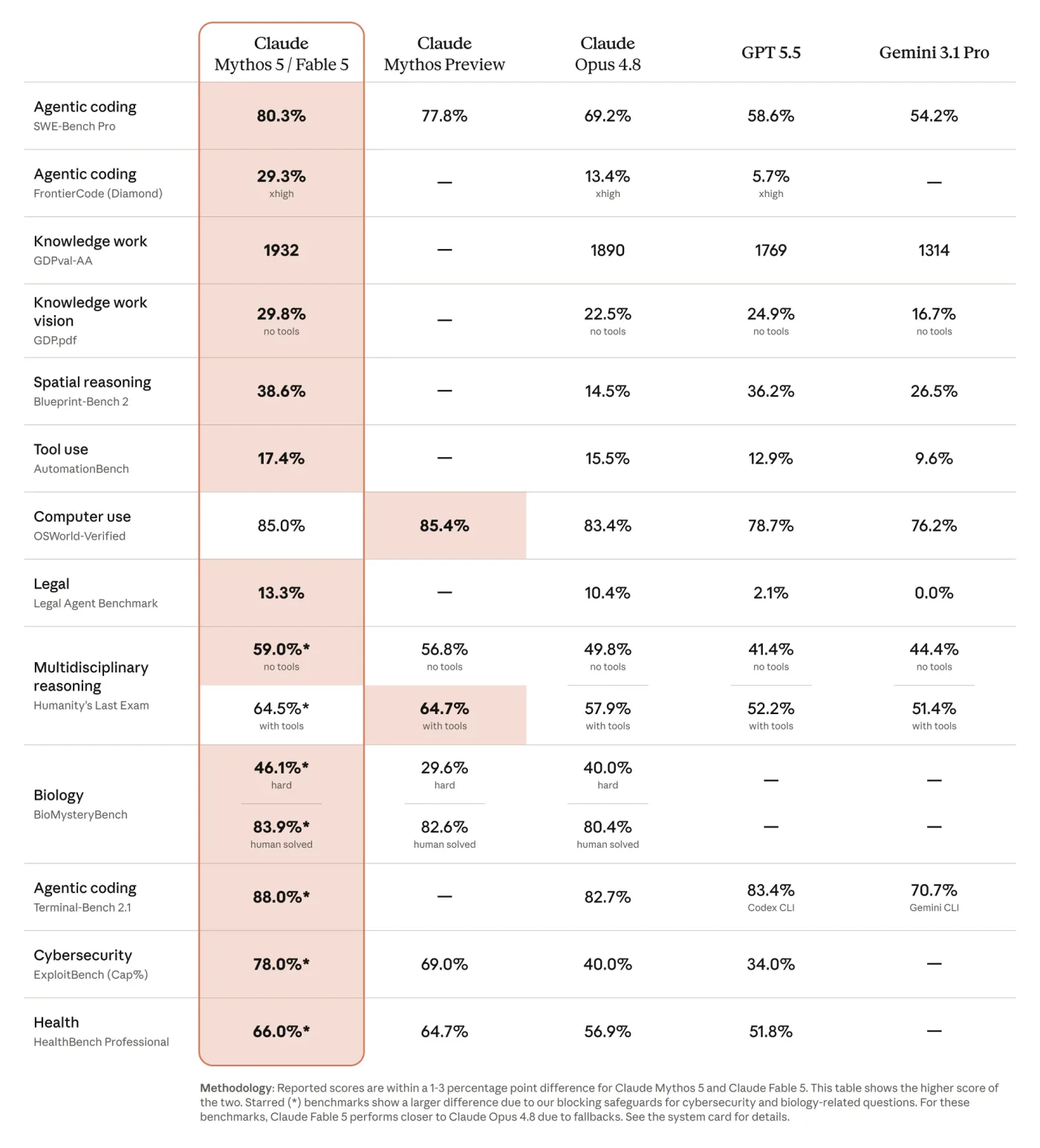
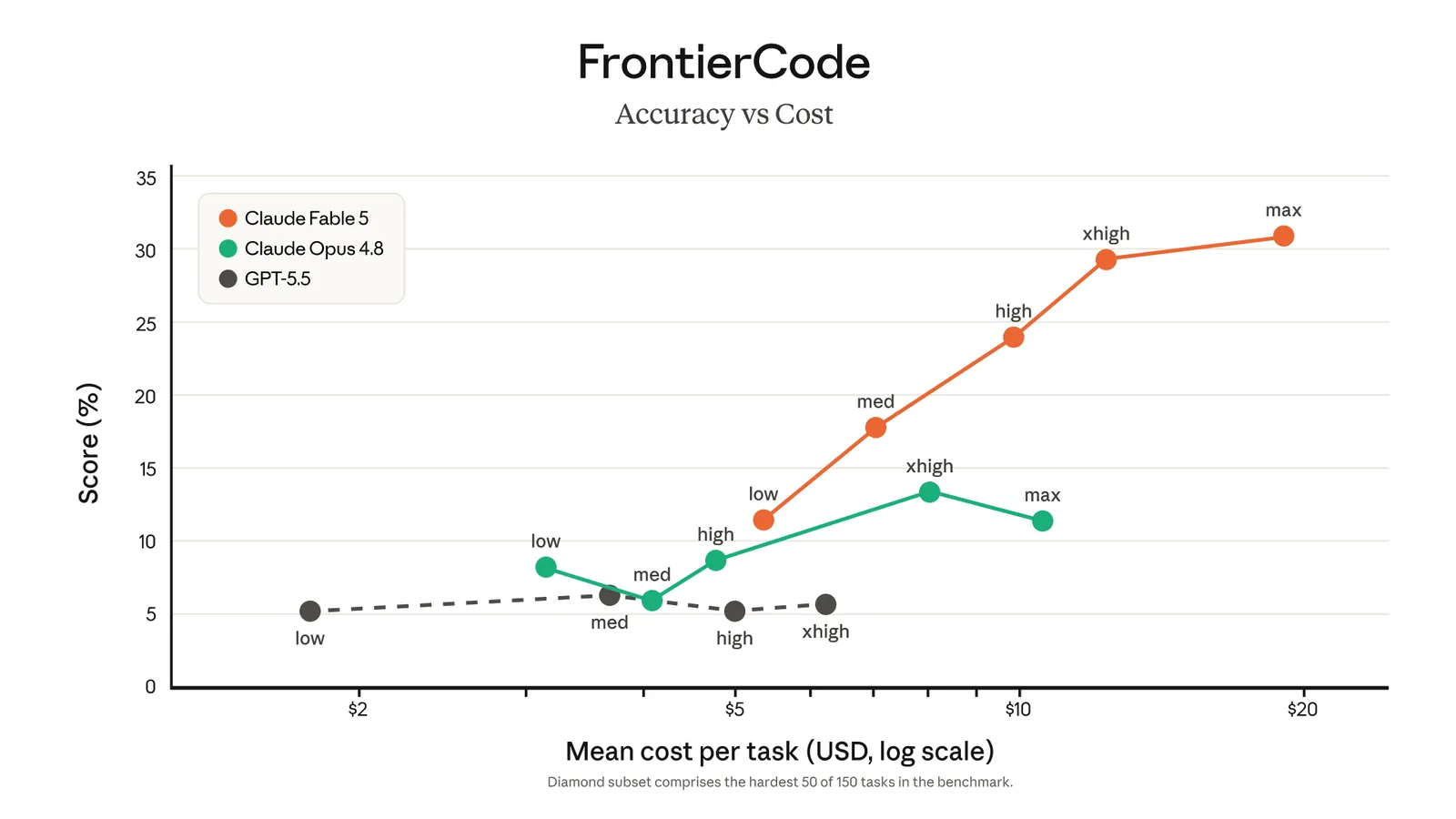
Agentic software engineering
The model can inspect repositories, plan changes across files, implement code, run tools, and revise its approach after failures. Anthropic reports strong SWE-Bench Pro and Terminal-Bench 2.1 results. Teams should still require version control, tests, review gates, and restricted credentials.